Highlights
- A large-scale video dataset. 44k hours of diverse human egocentric videos, the largest dataset to date for world model pretraining.
- A foundation world model. The first robot world model of its kind that demonstrates strong generalization to diverse objects and environments after post-training.
- A distillation pipeline. After distillation, our model can achieve long-horizon autoregressive generation, with stable real-time interactions at 10 FPS for over 1 minute.
Method
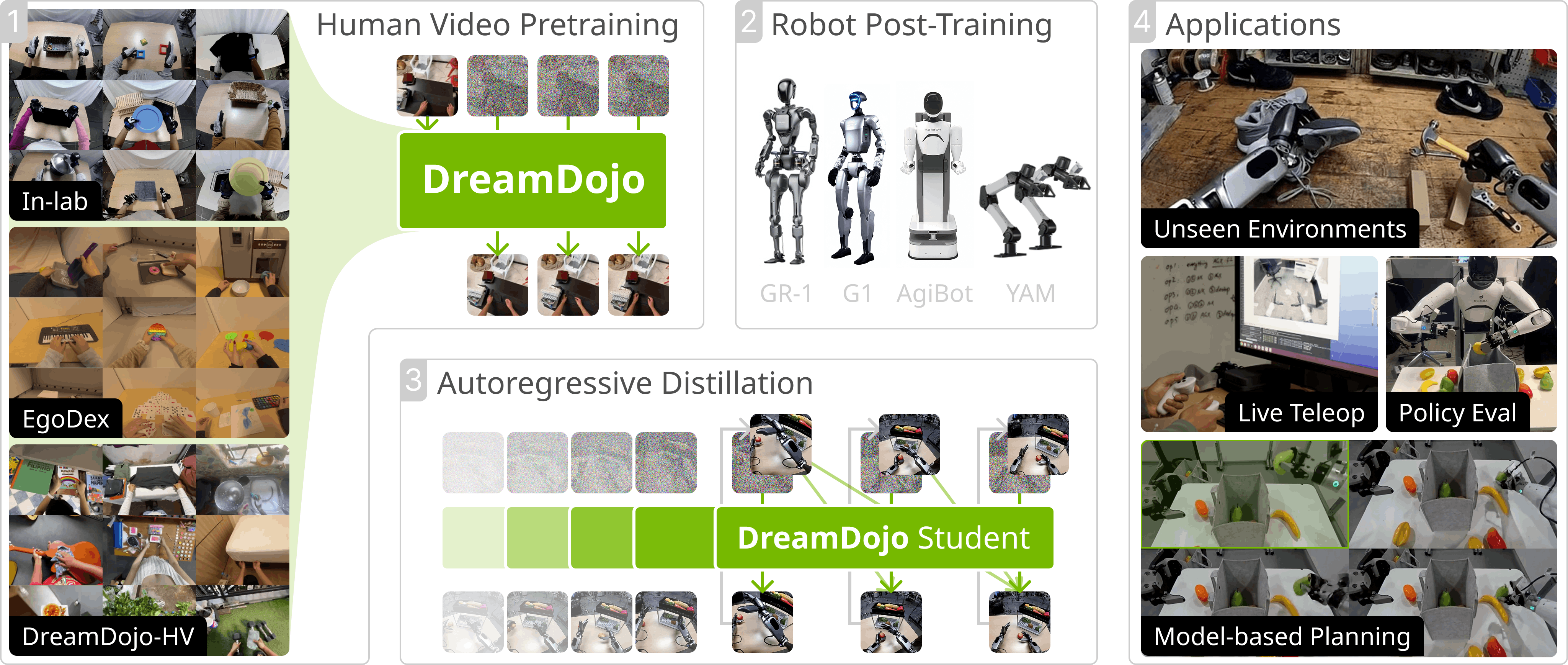
Method Overview. DreamDojo acquires comprehensive physical knowledge from large-scale human datasets by pre-training with latent actions, followed by post-training on the target embodiment with continuous robot actions.
DreamDojo-HV Dataset. Our dataset excels in both scale and diversity, encompassing 15x longer duration, 96x more skills, and 2,000x more scenes than the previously largest dataset for world model training.
Object and Environment Generalization
Diverse Environments and Objects. DreamDojo produces realistic action-conditioned rollouts for the GR-1, G1, AgiBot, and YAM across a wide range of environments and object interactions. Videos generated by the post-trained model.
Baseline vs DreamDojo Comparison. DreamDojo generates more accurate physical interactions due to its large-scale human data pretraining. We compare post-trained Cosmos-Predict 2.5 (left) with post-trained DreamDojo (right).
Real-Time Long-Horizon Rollouts
Teacher vs Student Comparison. DreamDojo reaches real-time 10 FPS generation through autoregressive few-step distillation. We evaluate on 1-minute long rollouts and compare speeds before (left) and after (right) distillation.
Downstream Applications
Live Teleoperation. We showcase DreamDojo's real-time capabilities by teleoperating and generating online rollouts.
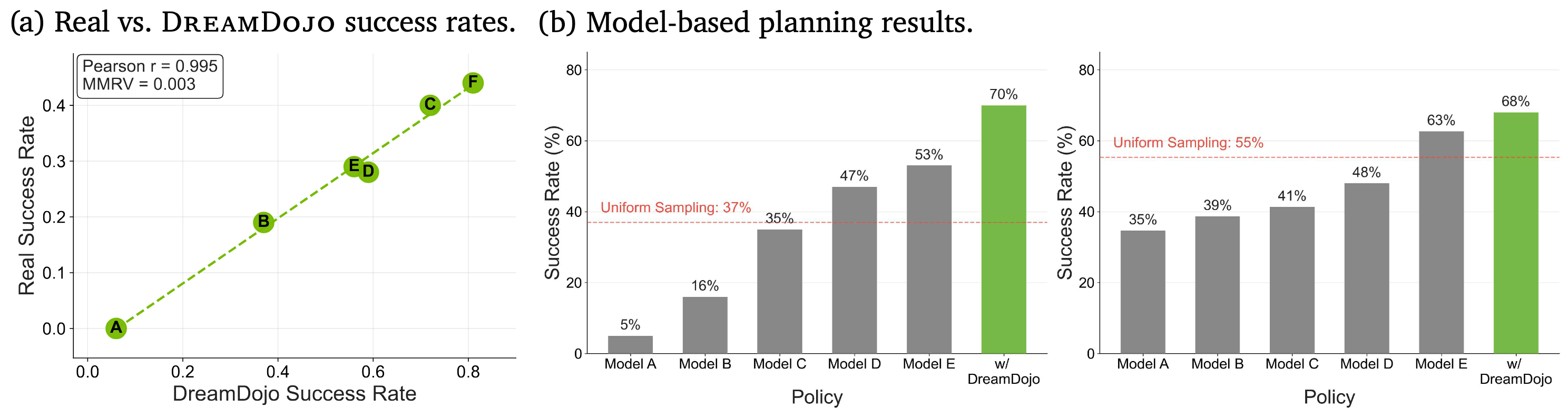
Policy Evaluation and Model-based Planning. We demonstrate the key applications of DreamDojo for reliable policy evaluation without real-world deployment and model-based planning for test-time improvement.
BibTeX
@article{gao2026dreamdojo,
title={DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos},
author={Shenyuan Gao and William Liang and Kaiyuan Zheng and Ayaan Malik and Seonghyeon Ye and Sihyun Yu and Wei-Cheng Tseng and Yuzhu Dong and Kaichun Mo and Chen-Hsuan Lin and Qianli Ma and Seungjun Nah and Loic Magne and Jiannan Xiang and Yuqi Xie and Ruijie Zheng and Dantong Niu and You Liang Tan and K.R. Zentner and George Kurian and Suneel Indupuru and Pooya Jannaty and Jinwei Gu and Jun Zhang and Jitendra Malik and Pieter Abbeel and Ming-Yu Liu and Yuke Zhu and Joel Jang and Linxi "Jim" Fan},
journal={arXiv preprint arXiv:2602.06949},
year={2026}
}